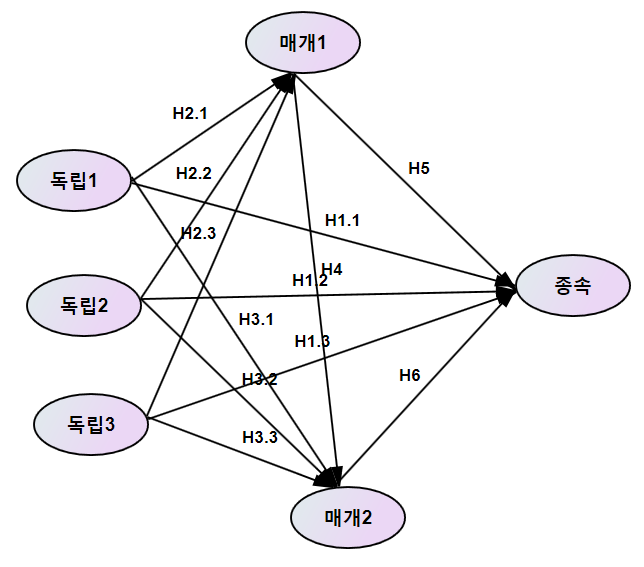
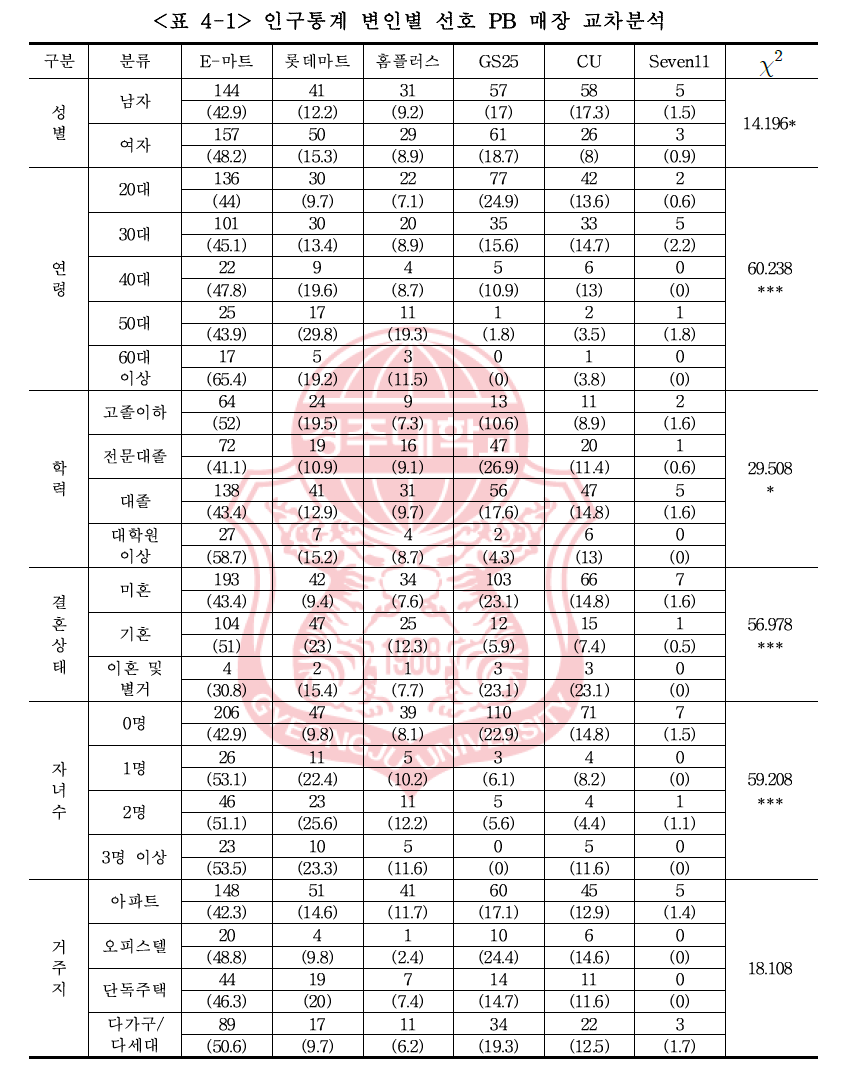
독립변수가 하나가 아니라 여러개가 있는 경우 다중회귀분석이라고 하여 단순회귀분석과 구별을 하는데 사실 통계학에서는 구별을 하지 않습니다. 이런 구별은 대학교 1학년 기초 통계학에서 구별을 하죠. 오늘은 독립변수가 여러개, 즉 X1, X2, X3가 있다고 하죠. 그럼 회귀모형식은 Y=b0+b1*X1+b2*X2+b3*X3+e 이라 하죠. 1. 독립변수가 서로간 독립인 경우 : 상관계수를 구해 보니까 독립변수들간에 상관계수가 전부 0일 경우 이 경우 특별히 2개의 독립변수가 orthogonal 하다는 표현을 씁니다. 현실에서는 절대로 나올 수 없지만 이론적으로 만들 수가 있습니다. 탐색적 요인분석을 하여 요인점수를 저장하여 이 요인점수를 독립변수로 사용하면 됩니다. 이 경우 요인점수는 표준화되어 있..