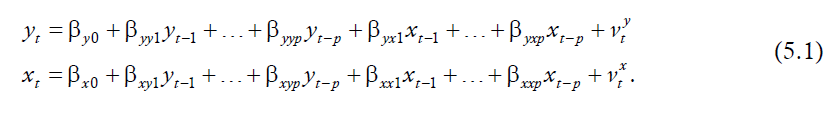1. R은 interpreter입니다. 아직 interpreter를 잘 모르는 분들이 있을 것 같은데요. 옛날부터 아니 지금까지 프로그램을 한다고 하면 프로그램 소스코드를 짠 다음 컴파일(compile)라는 것을 해야 합니다. 그래서 컴퓨터 안에서 돌아갈 수 있는 기계어 비슷한 것으로 바뀝니다. C, C++, 포트란, 맥의 Objective C 전부 다 compile 언어입니다. 다만 Java만 좀 다릅니다. 혼종이죠. R은 interpreter이고 compile 할 필요가 전혀 없습니다. 프로그램이 필요한 중요한 모듈은 이미 거의 다 만들어져 있고, 작업하는 사람은 이미 만들어진 모듈의 이름을 알아서 불러오기만 하면 됩니다. 최근에 인기가 많은 파이썬도 아마 interpreter 가능성이 높습니다...