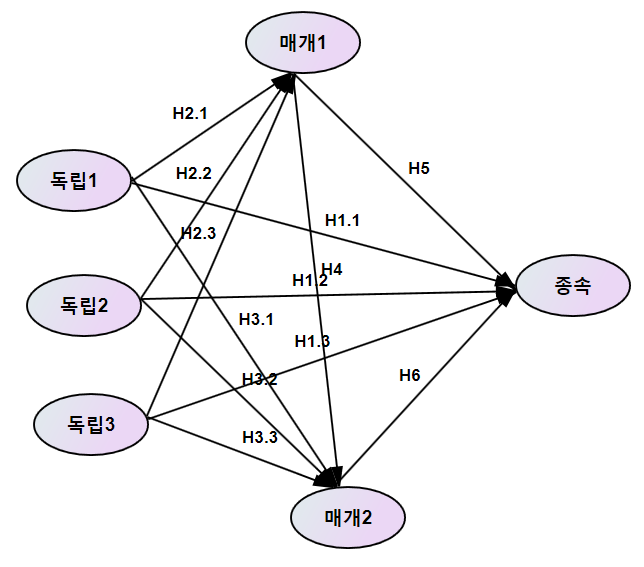
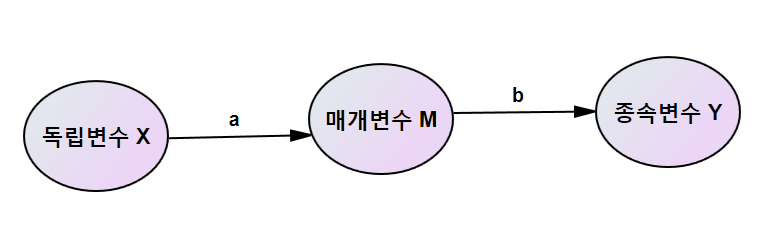
오늘은 박사수준의 구조방정식 모형을 소개하고자 합니다. 박사수준의 구조방정식 모형은 통상 석사수준의 구조방정식 모형에다 조절효과를 보는 것입니다. 여기서 조절효과를 본다는 것은 구조방정식 책에 있는 다중집단 분석을 한다는 이야기입니다. 우선 간단한 모형을 소개해보죠. A ==> B ==> C, 즉 독립변수 A, 매개변수 B, 종속변수 C가 있는 구조방정식 인과모형이 있다고 하죠. 여기에 조절변수 D를 끼워 넣는다는 것입니다. 예를 들어 설명하면 지난번 석사수준의 구조방정식 소개 글처럼 A은 운동량, C는 몸무게, B는 식욕이라고 하죠. 그림으로 그리면 운동량, 식욕, 체중과의 인과관계의 결과가 남자와 여자인 경우 다를 수가 있고, 또 비만이 사람과 아닌 사람에 따라 결과가 달라질 수 있습니다. 남자와 여..