사회과학논문에서 가장 많이 사용되는 연구방법론은 조절효과를 보는 Baron & Kenny(1986) 회귀분석이고요, 또 하나는 매개변수가 들어 있는 구조방정식 모형입니다. 이건 대부분 AMOS를 이용하여 분석하는데 최근에는 Baron & Kenny 방식에서 발전된 프로세스 매크로도 가끔 사용합니다.
그럼 이것 말고 다른 통계 방법론이 없을까 하는 생각이 들 수 있습니다. 위 방법론 등은 너무 흔해서요. 몇 가지 소개해 드리겠습니다.
1. 교차분석(Crosstabs Analysis)
이건 빈도분석에서 발전한 분석인데 옛날 석사 수준에서 자주 사용한 방법입니다. Likert 척도가 아닌 범주형 자료를 분석할 때 자주 사용하고 주로 현황을 파악하기 위해서 사용합니다.
예를 들어 한국을 방문한 외국인 관광객을 대상으로 다음과 같이 설문조사 할 수 있습니다.
1. 한국 음식 중 가장 좋아 하는 것은?
1) 김치류 2) 찌개류 3) 고기류 4) 김밥 등 길거리 음식
2. 한류 중 가장 좋아하는 것은?
1) k-pop 2) k-darama, movies 3) k-food 4) k-beauty
이런 식으로 설문조사를 할 수 있습니다.
이럴 경우 외국 관광객의 성별, 연령별, 소득별, 지역별, 인종별 등등에 따라 응답에서 차이가 있는지 보는 것입니다.
즉 범주형 변수와 범주형 변수간의 관계를 볼 수 있습니다.
여기서
1) 통상 질문 하나에 교차분석표 하나와 표 설명하면 거의 1페이지 정도 나옵니다. 그래서 질문 문항이 너무 많으면 분석 비용도 올라가고 페이지 수도 많이 잡아먹습니다. 그러나 이론적 배경에서 별 쓸 내용이 없고 그러면 분석 페이지를 많이 하는 방법도 있습니다.
2) 응답에서 중복을 허락하는 경우는 좀 골치 아픈 문제가 생깁니다. 분석 비용이 많이 올라갑니다. 그래서 가장 좋아하는 하나만 골라라 이렇게 설문조사하는 것이 좋습니다.
아니면 순위를 매기는 방법이 있습니다.
1. 한국 음식 중 가장 좋아 하는 것 1) 김치류 2) 찌개류 3) 고기류 4) 김밥 등 길거리 음식 중 2개만 고르세요.
1) 1순위( ) 2) 2순위 ( )
이렇게 질문할 수 있습니다. 이럴 경우는 골치 아픈 코딩 문제는 생기지 않습니다.
2. 대응일치분석(Correspondence analysis)
기본적인 성격은 위의 교차분석과 같은데 2개의 범주형 변수의 레벨간의 관계성에 대해 그래프로서 보여줍니다.
에를 들어 연령이라는 범주형 변수와 선호하는 한류라는 범주형 변수와의 관계를 20대는 k-pop과 가깝고, 50대 이상은 k-food, 30대는 k-beauty와 가깝다는 것을 그림으로서 보여 줍니다.
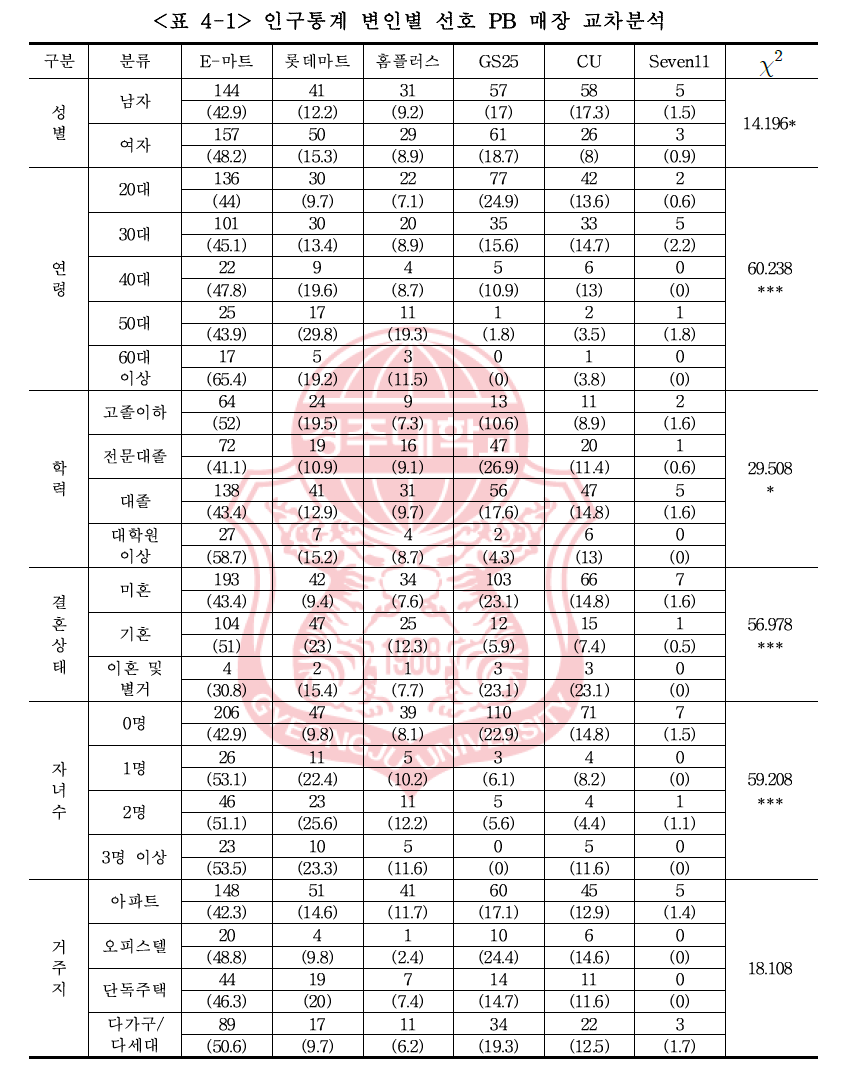
매장 유형과 연령대를 분석한 예를 보죠.

20대 이하는 GS25를 선호하고, 50대는 롯데마트를 선호하는 것이 분명히 보일 것입니다.
3. 군집분석(Clustering analysis)
이 분석은 요새 유형하는 MBTI랑 비슷한 분석입니다. MBTI는 4개의 성격 변인을 만들고 각 변인마다 평균 이상, 평균 이하 이렇게 2개로 나눕니다. 4개의 변인이 있으니까 2*2*2*2=16으로 16개 유형의 MBTI 유형이 나옵니다.
저는 이것 전혀 안 믿는데요. 사실 옛날에 한 2번 정도 의뢰가 들어와서 분석해 준 적이 있습니다. 그런데 전혀 안 맞습니다.
일단 16개 유형은 너무 많습니다. 한 200명 정도 설문조사하면 한 집단에 평균 20-15명 정도 밖에 안 나옵니다. 10명 이하의 집단도 있고요. 이렇게 적은 숫자의 집단으로 그 집단의 성격을 규명할 수 없죠. 즉 통계 결과를 믿을 수가 없다는 것입니다.
또 하나의 이론적인 문제는 4개의 성격 변인이 완전히 독립적이지가 않습니다. 즉 4개의 변인간에 서로 상관관계가 있어서 MBTI처럼 분류하면 안됩니다.
이 문제를 해결하는 방법이 통계학의 군집분석을 사용하는 것입니다. 흔히 가장 많이 쓰는 방법이 K-means 방식이 군집 수를 4-5개 정도로 잡아서 분석합니다.
연구변수에 A라는 독립변수와 B라는 종속변수가 있다고 하죠. A의 하위영역 변수가 5개 정도가 있다고 하고요. 그럼 A의 5개 하위영역 변인을 가지고 군집분석을 하여 집단을 유형화합니다. 그럼 다음 인구통계 변인별로 군집유형에서 차이가 있는지 교차분석하고 대응일치 분석 그래프 제시하고, 군집유형에 따라 종속변수 B에서 차이가 있는지 분산분석을 하면 됩니다. 즉
인구통계 ===> 군집유형 ==> 종속변수
이런 식으로 분석하면 됩니다.
이 주제의 핵심적인 요소는 군집이 잘되는가 아닌가입니다. 분류된 군집에 대해서 우리가 적절하게 이름을 붙일 수가 있어야 합니다. MBTI 16개 성격유형에 대해서 적절한 이름을 붙일 수가 있을가요?
4. 의사결정나무(decision tree)
이 방법론은 최근 유행하는 빅데이터 분석 기법입니다.
장사하는 사람에게는 최근 신제품을 어느 소비자 집단이 가장 많이 선호하고 어느 소비자 집단이 가장 싫어하는지 알고 싶을 겁니다. 표적마케칭(target marketing)이죠.
또는 노인 집단에서 어떤 집단이 자살을 하는지 알고 싶을 수도 있습니다. 즉 취약노인집단을 파악할 수 있습니다.
문제는 정확하게 제품을 산 사람의 여러 가지 정보, 또는 자살의 노인의 여러 가지 개인 정보를 알기가 힘들다는 것이죠.
이럴 경우 설문조사해서 제품을 살 의도, 또는 자살의도를 Likert 척도나 이진 변수로 물어 볼 수 있습니다. 즉 살 의도가 없다=0, 살 의도가 있다=1 이런 식으로 물어보면 됩니다.
그런 다음에 제품을 살 의도, 자살의도에 영향을 미치는 다양한 변인 등을 설문조사시 물어보고 의사결정 트리를 이용하면 됩니다.
구체적인 예를 한번 보죠.
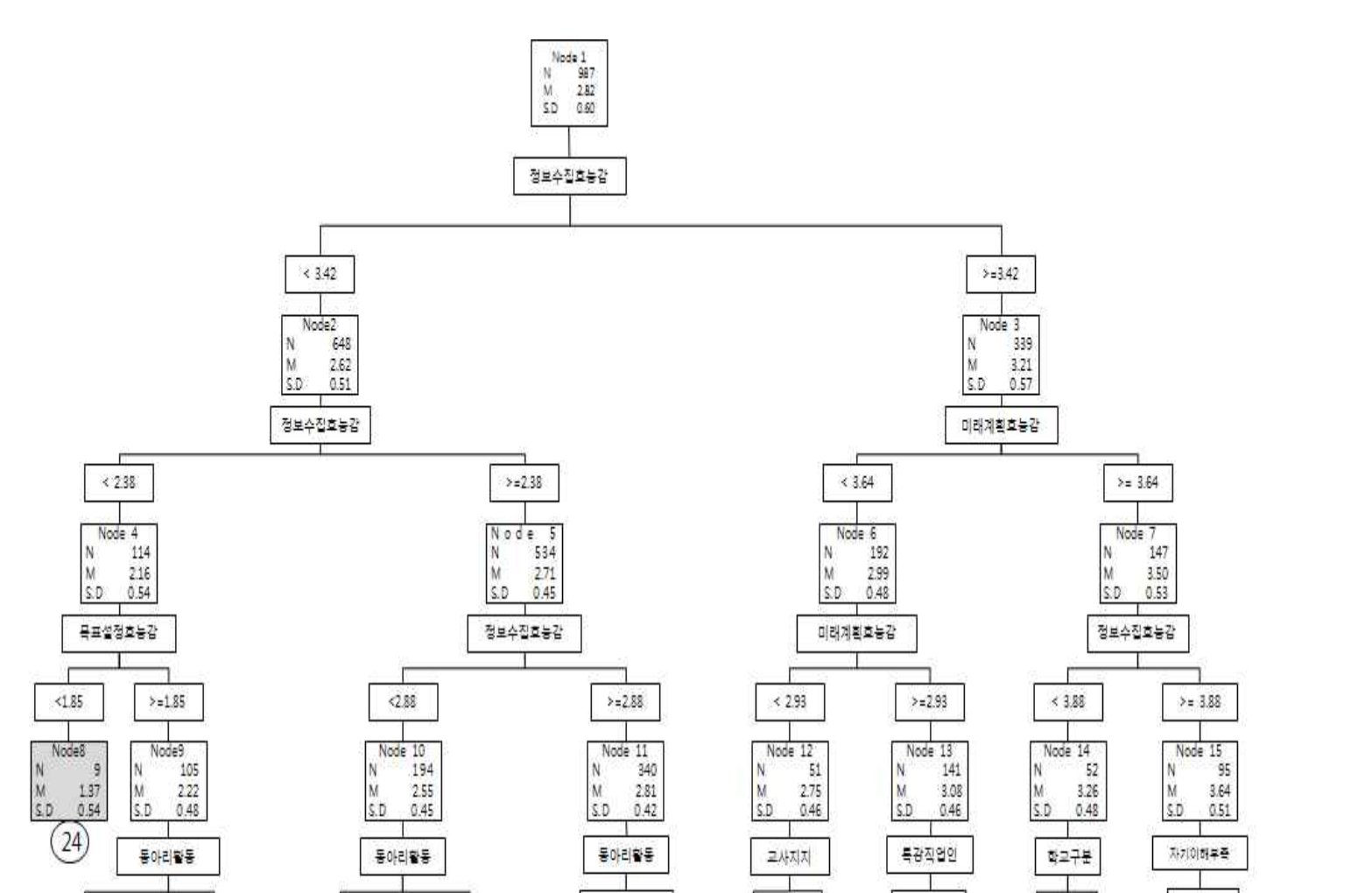
이 트리를 쭉 따라가면 살 의도가, 자살을 할 의도가 가장 높은 집단부터 가장 낮은 집단까지 분류가 가능합니다.
만약 분석 변수, 즉 종속변수가 이진변수이면 이때 평균 M은 확률이 됩니다. 즉 살 확률, 자살을 할 확률 이렇게 해석됩니다.
아마 가장 쉽게 논문을 쓸 수 있고, 현장에 도움이 많이 될 수 있는 방법론입니다.
5. 정준상관분석(Canonical Correlation analysis)
A라는 변수가 B라는 변수에 영향을 미친다는 인과관계가 있다고 하죠. 단 A의 하위변인은 6개, B의 하위변인은 5개라고 하죠.
그럼 A와 B의 연관성, 인과성을 분석하는 방법은
1) 상관분석
이 경우 6*5=30개의 상관계수의 정보를 알아야 합니다.
2) 회귀분석
종속변수 5개의 대해 독립변수 6개를 설정하면 이 경우도 6*5=30개의 회귀계수의 정보를 알아야 합니다.
더 큰 문제는 상관분석이나 회귀분석이나 6개의 독립변수간의 상관관계, 5개의 종속변수간의 상관관계가 고려하지 않는 분석이라는 점입니다.
그래서 독립변수 A의 하위변인간, 종속변수 B의 하위변인간의 상관관계를 고려하면서 A와 B의 관계를 좀 간략하게 볼 수 있는 방법이 없을까 하는 점입니다.
이게 정준상관분석입니다.
SPSS 옛날 버전에서는 scrip 파일로 숨어 있었는데 최근 SPSS 프로그램에는 메뉴로 나와 있네요.
상관분석==> 정준상관으로 가면 됩니다.
만약 spss에서 이 메뉴가 안보이면 옛날 버전 spss이고 그럼 인터넷 검색해서 정준상관 scrip을 찾아서 자신의 경우로 고치시면 됩니다.
아이디어는 간단합니다. A의 하위영역변수를 X1, X2, X3, X4, X5라고 하고 B의 하위영역 변수를 Y1, Y2, Y3, Y4 라고 하면
선형결합(X1, X2, X3, X4, X5)=Z1과 선형결합(Y1, Y2, Y3, Y4)=Z2간의 상관관계를 보여줍니다.
즉 Z1=(c1*X1+c2*X2+c3*X3+c4*X4+X5*X5)
와 Z2=(d1*Y1+d2*Y2+d3*Y3+d4*Y4)
의 상관계수가 가장 높게 나오는 c와 d값을 구해줍니다. 또 2번째로 상관계수가 높게 나오는 c와 d값을 구해 줍니다.
그림을 그려 보면 다음과 같은 개념입니다.
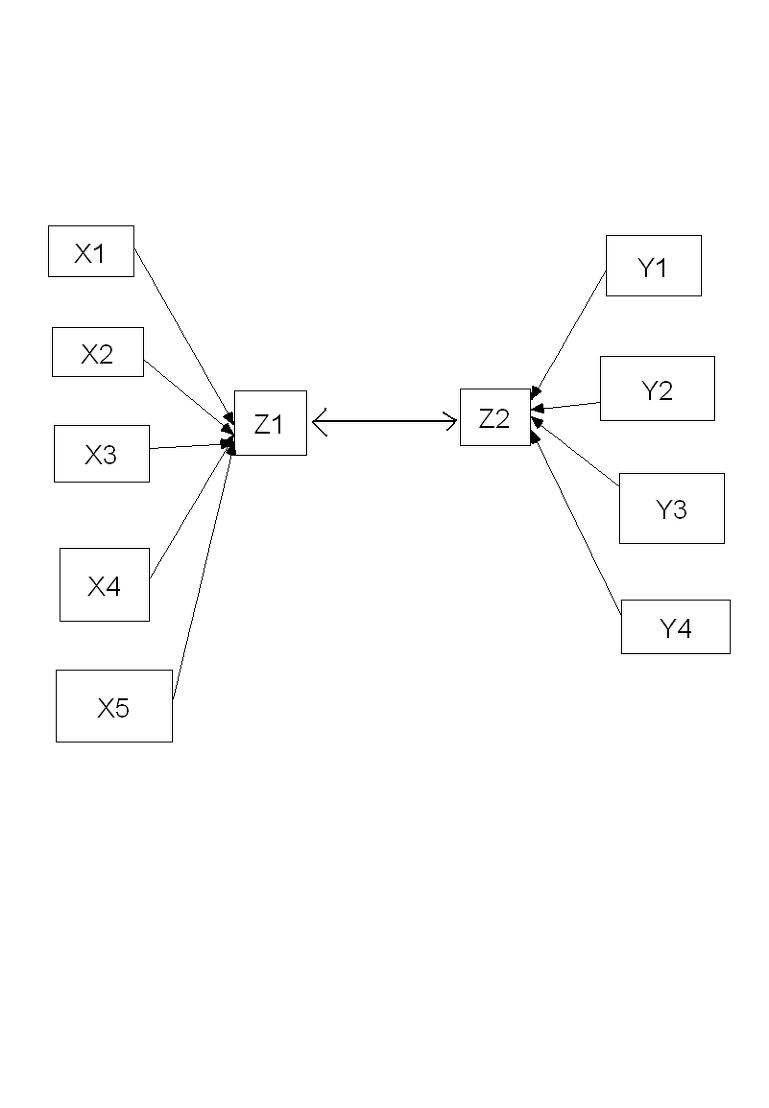
그래서 표준화 계수 c와d가 높은 경우만 알면 됩니다.
아래는 실제 논문의 나온 결과입니다.
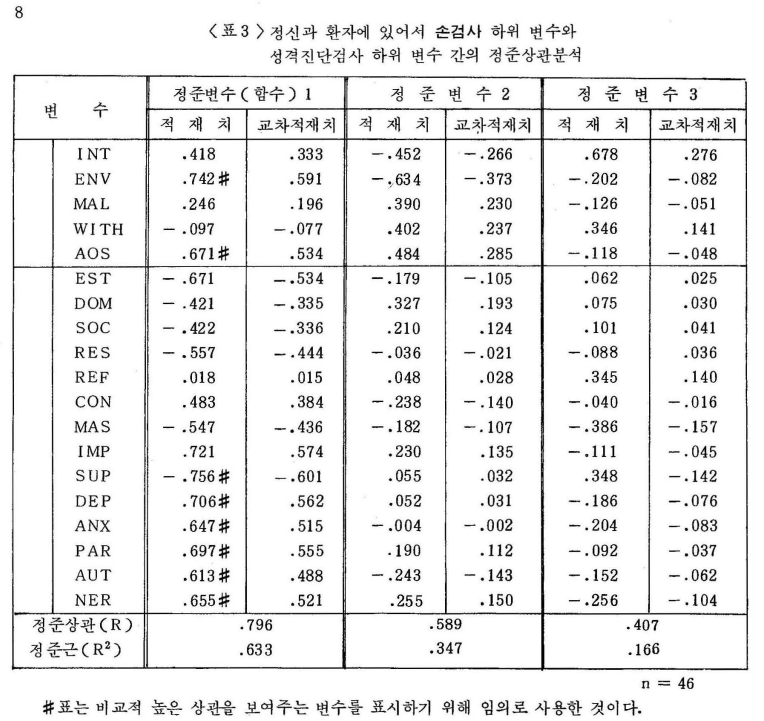
A는 4가지 손검사 유형과 B는 16가지 성격 유형을 정준상관분석한 결과입니다.
정준함수1이 가장 상관관계가 높은 경우이고 손검사의 env와 aos와 성격유형 sup, dep, anx,... 등등과 상관관계가 높습니다. 결과보면 그래 결과가 좋아보이지 안습니다. 앞에서 이야기했지만 성격유형은 잘 안 맞아 떨어집니다. 좋은 결과는 2개 정도 변수는 적재치가 0.5 이상 높게 나오고 나머지는 0.2 이하로 매우 낮게 나와야 합니다.
보면 아시겠지만 정준상관분석은 하위변인이 많을수록 그 효용성이 높습니다. 그러나 한 가지 문제가 뭐냐면 결과물이 너무 적습니다. 즉 위 표 하나로 끝납니다. 학위논문 쓰기가 좀 그렇죠.
만약 3개의 변인, A, B, C가 있으면 (A, B). (B, C), (A, C) 이렇게 3개의 표를 도출해서 논문에 넣을 수 있겠습니다.