오늘은 구조방정식에서 나오는 모형선택 문제의 제일 마지막입니다. 즉, 잠재성장모형 또는 잠재성장곡선모형에서 나오는 모형선택에 관해서 소개하겠습니다.
이건 구조방정식 책에 나오는 책도 있고, 없는 책도 있습니다. 그냥 개념만 알려드립니다.
먼저 잠재성장모형을 이용해서 논문을 쓰시려고 하면 다음과 같은 점을 아셔야 합니다.
1) 잠재성장모형은 패널데이타를 사용합니다.
주로 정부에서 나오는 개인을 대상으로 매년 조사하는 자료를 사용합니다.
2) 측정하는 해에 따라 변수들이 변해야 합니다.
불행하게도 대부분의 성인들은 세월이 흘러도 인식이 잘 안변합니다. 최소한 5년, 또는 10년 정도 흘러야 인식이 바뀝니다. 따라서 잠재성장모형을 이용하여 논문을 쓸 경우 생각이 자주 바뀌는 청소년 대상 패널데이타를 많이 사용합니다. 특히 중학교 진학과 고등학교 진학 경우 많이 바뀌죠.
예를 들어 일반청소년을 대상으로 부모양육태도, 교우관계, 교사관계, 그리고 일탈행위 등 조사한 데이터나 또는 다문화 청소년을 대상으로 조사한 데이터 등이 있습니다.
3) 연구모형의 연구변수들이 선형으로 변해야 합니다.
구조방정식 책을 보면 연구변수들의 변화 모형에 대해서 여러 가지가 나오는데 실제 알 필요가 있는 것은 무변화, 선형변화, 2차 변화 모형 이 3가지 뿐입니다. 또 이 중에서 선형변화로 움직여야 실제 논문을 쓸 수 있습니다.
연구변수가 시간에 따라 변화가 없는 무변화의 경우나 2차함수 형태로 변하는 경우 인과관계 분석에서 아무런 의미가 없거나 해석이 사실상 불가능합니다. 따라서 연구모형의 연구변수가 시간에 따라서 선형으로 변한다는 것을 사전에 확인을 해야 합니다.
좋은 방법은 정부에서 조사하는 패널데이타는 조사하는 변수들이 매우 많습니다. 따라서 모든 변수들의 시간별 평균값을 조사하여 이 평균값이 어떻게 변하는지 사전에 알아보는 것입니다. 그래서 직선형태로 변하는 변수 중에서 연구변수를 선정하는 것이 좋습니다.
4) 측정연도는 1년 단위로 할 필요가 없다.
정부 패널데이타는 매년 조사하는 경우가 대부분이지만 잠재성장모형을 적용할 때 매년 자료로 할 필요는 없습니다. 앞에서 이야기했지만 사람들의 인식이나 상황이 매년마다 확 변하지 않습니다. 따라서 2년, 또는 시간별 충분한 자료가 있으면 3년마다 측정한 값을 가지고 잠재성장 모형을 적용할 수 있습니다.
그럼 amos에서 잠재성장모형을 적용하면 다음과 같은 그림이 뜹니다. amos에서는 디폴트로 선형모형을 가정하고 그림을 그려줍니다. 구태여 무변화나 2차변화모형을 적용하려면 이 그림에서 본인이 직접 손을 봐야 합니다.

연구변수의 변화 모형이 무변화, 선형변화, 2차변화 중 어떤 변화를 하는지 선택을 해야 합니다. 즉 통계적으로, 이론적으로 선택을 해야 합니다.
| 모형 | 모형식 |
| M0 | X(t)=b0 |
| M1 | X(t)=b0+b1*t |
| M2 | X(t)=b0+b1*t+b2*t^2 |
여기서 M0 < M1 < M2 관계가 있음을 알 수 있습니다. 즉 가장 복잡한 모형 M2에서 b2=0이라는 제한을 주면 조금 간단한 모형 M1이 되고, 이 M1에서 b1=0이라는 제한조건을 주면 가장 간단한 모형 M0이 됩니다.
1) 조절효과를 보는 위계적 회귀분석 모형과 비교
흔히 조절효과를 볼 때 3단계 위계적 회귀분석을 하죠. Y를 종속변수, X를 독립변수, M을 조절변수라고 하면 이 경우
M0: Y=b0+b1*X
M1: Y=b0+b1*X+b2*M
M2: Y=b0+b1*X+b2*M+b3*XM
이렇게 되죠. 그래서 가장 복잡한 모형 M2에서 b3=0 제한을 주면 조금 간단함 M1이 되고 여기서 b2=0이라는 제한 조건을 주면 가장 간단한 M0모형이 됩니다.
2) 회귀계수의 해석
이 잠재성장모형을 이해하기가 쉽지 않는데요. 그 이유는 회귀계수가 일반적인 회귀분석의 경우나 아니면 잠재성장모형이 아닌 다른 구조방정식 모형에 나오는 회귀계수랑 다르기 때문입니다.
위의 잠재성장 모형의 그림에서 회귀계수는 이미 지정되어 있습니다. 이 이 지정된 회귀계수는 시간 t 변수로 해석하는 것이 맞습니다. 선형인 경우 t=0, 1, 2, 3이 되고, 2차 변형모형에서는 회귀계수는 t^2인 0, 1, 4, 9로 지정해야 합니다.
그럼 우리가 구해야 하는 회귀계수는 어떻게 구해야 하나요? 잠재성장모형을 돌리면 자동적으로 구해 줍니다. 즉, 3가지 모형 M0, M1, M2를 각각 돌리면 각 모형에 해당하는 회귀계수 b 0, b1, b2를 구해줍니다.
실제 결과값을 한번 볼까요. Estimate에 가면 결과물이 있습니다. 이 회귀계수의 해석은 다음 글에서 쓰겠습니다.
모형 M0의 경우
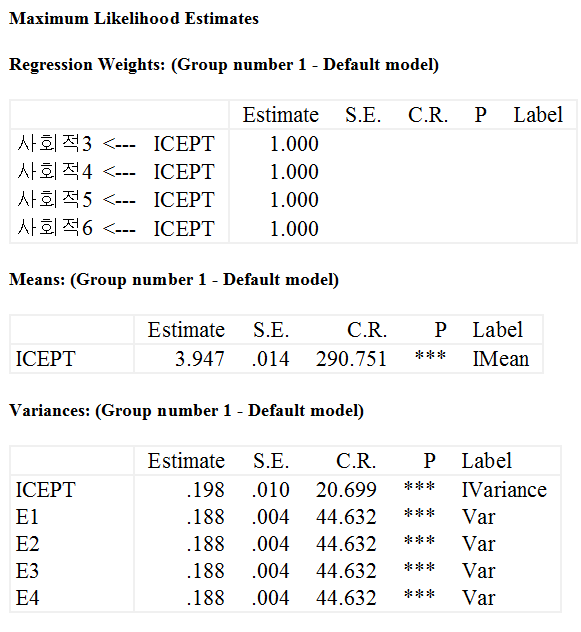
모형 M1의 경우

표 중간에 Means에 결과물이 있죠, 결과물을 보면 선형변화 모형인 M1의 경우 b1이 유의적이지 않기 때문에 이 경우 모형 M0을 선택해야 합니다. 그러나 진짜 제대로 하려면 M2까지 해 봐야 합니다. 왜냐하면 b1이 0이 아니라고 해도 모형 M2에서는 2차항 b2가 유의적으로 나올 수 있 또 모형 M2에서는 b1이 유의적으로 변할 수도 있습니다.
이렇게 복잡하게 생각하면 끝이 없습니다. 그래서 대부분 무변화 M0과 선형변화 M1 모형만 하고 끝냅니다. 대부분 사회과학 교수들이 이론을 제대로 이해를 못하기 때문에 더 이상 복잡한 것을 요구하지 않습니다.
실제 저널 논문의 경우를 한번 볼까요.
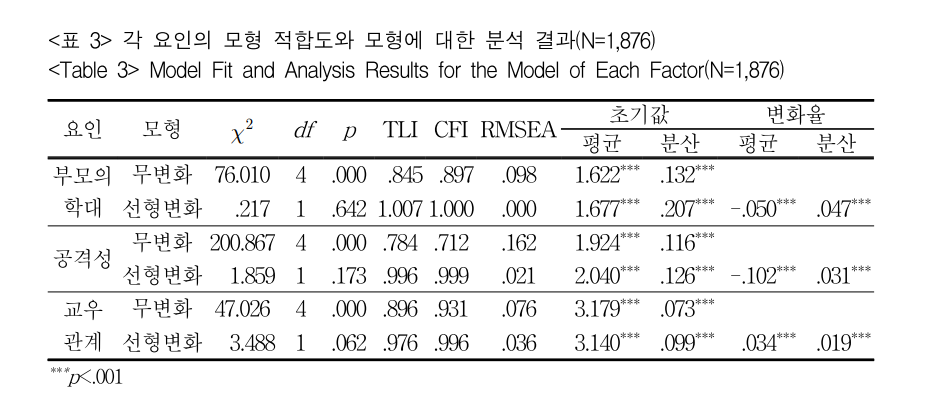
부모의 학대 변수의 경우 무변화 M0모형에서 회귀계수 b0=1.622***로 유의적으로 나왔고, 선형변화 M1모형에서 회귀계수는 절편 b0=1.677***, 기울기 b1=-0.050***으로 유의적으로 나와 선형모형을 선택하는 것이 좋습니다.
또 3개의 변수에 대해 각 모형에 대한 카이제곱 통계량이 있는데 이건 전에도 설명했듯이
귀무가설 H0: 현재 모형이 좋다
대립가설 H1: 가장 복잡한 모형이 좋다
이 가설을 검증하는 것입니다. 따라 부모 학대의 경우 무변화는 카이제곱 검증이 유의적으로 나왔기 때문에 더 복잡한 모형을 선택하는 것이 좋다고 나왔지만(카이제곱=76.010***) 선형변화에서 카이제곱은 유의하지 않아(카이제곱=0.217, p>.05)로 나왔기 때문에 더 복잡한 모형으로 하지 말고 현재 모형인 선형모형 M1이 좋다는 이야기입니다. 밑에 공격성, 교우관계도 같은 해석이 되고요.
그러나 이 논문에서는 카이제곱 해석은 하지 않았습니다. 뭘 의미하는지 잘 모르니까 그런 것이죠.
다른 저널 논문 결과를 한번 보죠.
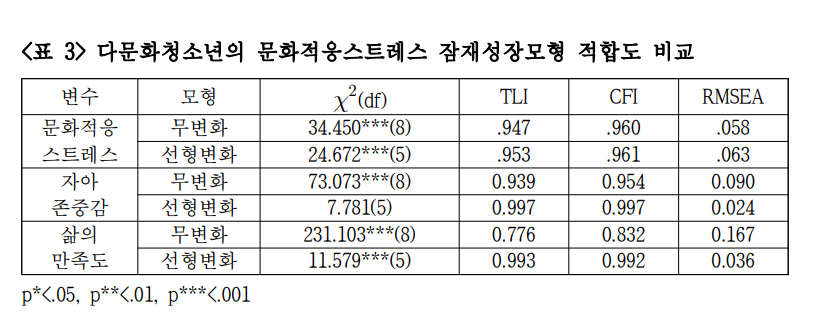
문화적응스트레스와 삶의 만족도에서 선형변화모형 M1의 카이제곱 값은 유의적으로 나왔습니다. 즉, 좀 더 복잡한 모형을 추구하라는 이야기죠. 따라서 이차변화모형 M2까지도 고려해야 한다는 것입니다. 그러나 그렇게 안했죠. 이 논문에서도 이 카이제곱 해석을 하지 않았습니다.
더구나 이 카이제곱은 현재 모형과 포화모형(가장 복잡한 모형)간의 선택을 검증하는 것이지 무변화모형 M0와 선형모형 M1중 어떤 모형을 선택할 것인지, 또는 선형모형 M1과 이차변화모형 M2중 어떤 모형을 선택할 것인지 검증하는 통계량이 아닙니다.
이 문제는 다음 글에서 다루기로 하죠.
복잡한 것 같지만 간단하게 정리하면
1) 연구변수는 선형변화를 하는 변수로 선정한다.
2) 무변화 모형 M0와 선형변화모형 M1만 비교한다
3) 선형변화모형에서 절편 b0과 기울기 b1이 유의적으로 나오고, M0일 경우보다 M1인 경우 적합도가 상당히 양호해졌다는 것을 지적한다.
4) 카이제곱 통계량은 가능하면 언급하지 않는 것이 좋다.
이 부분은 다음 글에서...
'구조방정식.매개모형,SEM,AMOS' 카테고리의 다른 글
| 잠재성장모형 모형선택 (0) | 2022.10.01 |
|---|---|
| 측정동일성 모형선택 (1) | 2022.09.19 |
| 구조방정식 조절효과 모형선택1 (0) | 2022.09.10 |
| 구조방정식에서 모형선택과 가설검증1 (0) | 2022.08.29 |
| 모델7:조절된 매개지수 (0) | 2022.06.21 |