오늘은 지난번에 이어 조절효과에서 측정동일성 검증이라는 모형선택 부분을 이야기해보죠. 이 측정동일성 검증은 현재 오직 모형선택 이론만으로서 설명될 수 있습니다.
지난번에서도 이야기했지만 이 부분은 석사논문에서는 거의 요구하지 않고 박사논문에서 가끔 잘난 체 하는 심사위원들이 요구하는 경우가 있습니다. 요구하면 해야죠. 별 수 없죠.
만약 심사위원이 이걸 요구하면, 또 본인이 직접해야 하는 경우라면 먼저 시중 책방에서 구조방정식 측정동일성 부분이 있는 책을 먼저 구입하시기 바랍니다. 조금 복잡합니다.
측정동일성 문제가 뭔가 예를 들어서 설명해보죠.
연구가설이
스트레스 ==> 소진,
스트레스가 소진에 영향을 미치는지 검증한다고 보죠. 그래서 스트레스 측정을 위해 스트1, 스트2, 소진 측정을 위해 소진1, 소진2 설문문항을 만들어 설문조사를 했다고 하죠.
이 경우에 스트레스 ==> 소진 이 영향관계가 남녀간에 차이가 있는지, 즉 회귀계수가 남녀간에 차이가 있는지 알아보고 싶다는 것이죠. 즉 조절효과를 보는 것입니다.
그런데 남녀 각각 스트레스 ==> 소진 이 관계를 돌리기 전에 스트레스와 소진이 남녀간에 동일한 변수임이 먼저 검증이 되어야 합니다.
구체적으로 확인적 요인분석에서 아래 그림처럼
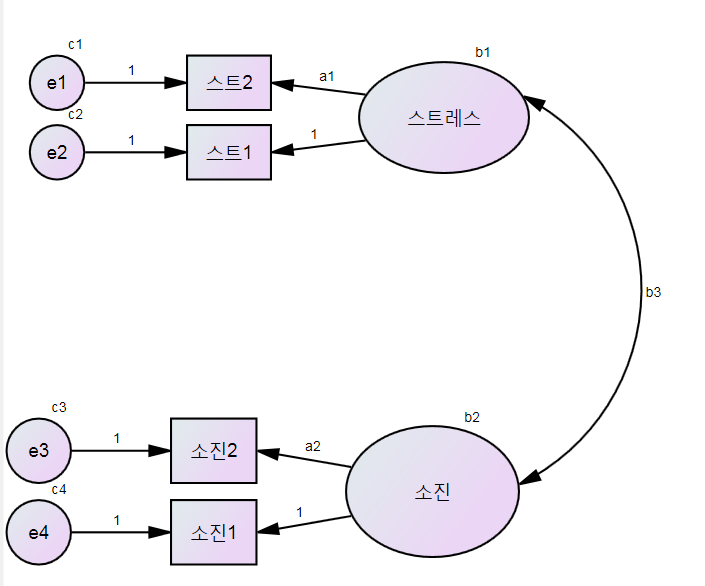
위의 확인적 요인분석을 돌리면 amos에서 크게 3 부분의 값을 구해줍니다.
가장 중요한 중앙 부분인 회귀계수값입니다. 두 번째는 오른쪽에 있는 잠재변수들간의 공변량 행렬. 즉 잠재변수의 분산과 공분산입니다. 마지막으로 왼쪽에 있는 오차항 e에 있는 분산 값입니다. 오차항의 평균은 0으로 미리 지정되어 있습니다.
이 값들은 amos 결과물에서 estimates==> scalars에 가면 확인할 수 있습니다.
측정 동일성 문제는 남녀간의 위 세 부분의 값들이 통계적으로 같은가 알아보는 것입니다.
만약 이 세부분의 값들이 통계적으로 같지 않다고 잠재변수 스트레스와 소진이 남녀간에 값이 다르다고 볼 수 있습니다.
그럼 이렇게 다른 값을 가진 변수들을 가지고 남녀간에 각각 스트레스 ==> 소진 인과모형을 돌려 나온 회귀계수 값을 가지고 차이가 있는지 없는지 따지는 것 자체가 어불성설이라는 것이죠.
여기서 이 3부분이 남녀간에 같은지 다른지 따지는 측정동일성 문제는 복잡하게 생각하지 말고 그냥 amos에서 디폴트로 주어지는 경우만 하시면 됩니다.
1) 확인적 요인분석,
즉, 확인적 요인분석을 위한 측정모형 그림을 그립니다.
2) 그 다음 집단(group)
남자, 여자 집단을 만들고 이걸 각 성별로 데이터와 연결합니다.
이건 조절효과 볼 때 항상 하는 일이죠. 여기서 성별로 각각 따로 데이터를 만들 필요는 없습니다. amos에서 데이터 메뉴로 가서 group가 값을 지정하면 됩니다. 만약 남자가 1, 여자가 2로 코딩되어 있으면 group value를 남자는 1, 여자는 2로 지정하면 됩니다. 그럼 amos가 알아서 분석할 때 데이터를 쪼개서 남자, 여자 따로 분석을 합니다.
3) 그 다음 모형 부분
이 부분은 걱정하실 필요가 없습니다.
아래 amos 메뉴에서

정 가운데에 있는 사람들이 마주보고 있는 그림을 클릭하시면 됩니다. 그럼 다음과 같은 메뉴가 다시 뜹니다.

여기서 그냥 OK 하시면 됩니다. 그럼 자동적으로 모형 4개가 생성되고 각 모형에 대한 제한조건등이 자동적으로 생성됩니다. 그래서 바로 돌리면 amos에서 제공하는 디폴트 측정동일성 검증을 해 줍니다. 그리고 심사위원도 이 디폴트 이상의 복잡한 측정동일성을 요구하지 않을 겁니다. 심사위원도 정확한 개념을 모르거든요.
이 메뉴는 3개의 모형을 보여줍니다. 이 3개의 모형의 개념만 잘 이해하시면 됩니다.
1) M2: measurement weights 모형.
이 모형은 남녀간에서 앞에서 이야기한 a 부분, 즉 회귀계수 부분만 같고 다른 부분, 즉 b나 c 부분은 남녀간에 다를 수 있다.
2) M1: structural covariance 모형.
앞에서 이야기한 맨 오른쪽, 즉 잠재변수의 분산과 공분산 부분 즉, b 부분이 남녀간에 같고, 여기에 더해 1)의 회귀계수 부분 즉, a 부분도 같다. 단지 c 부분만 남녀간에 다를 수 있다.
3) M0: measurement residual 모형.
이 모형은 3 부분, 즉 남녀간에 a 부분, b 부분, c 부분 모두 다 같다.
여기서 추가적으로
4) M3: default 모형이 있습니다.
즉 남녀간에 a, b, c 이 3부분 중 어느 하나라도 다를 수 있다라는 모형입니다.
시중에 나와 있는 구조방정식 책을 보면 이 모형선택의 개념을 잘 모르기 때문에 대개 복잡하게 설명이 되어 있습니다.
간단한 원칙입니다. 제한 조건이 많을수록 단순한 모형이고 제한 조건이 적을수록 복잡한 모형입니다.
그래서 가장 간단한 모형이 M0(a, b, c 다 같다), 그 다음이 M1(a와 b 만 같다), 그 다음이 M2(a만 같다), 그리고 가장 복잡한 모형이 M3 즉 디폴트 모형인 비제한 모형으로 남녀간에 a, b, c 중 하나라도 다를 수 있다라는 모형입니다.
즉 M0 < M1 < M2 < M3 이렇게 됩니다.
그래서 원칙적으로 측정동일성 검증은
귀무가설 H0: M0, 즉 남녀간에 a, b, c 모두 다 같다
대립가설 H1: M3, 즉 남녀간에 a, b, c 하나라도 다를 수 있다.
이렇게 됩니다. 그럼 amos에서 측정동일성을 돌리면 다음과 같은 결과를 얻을 수 있습니다.

위 그림 중 제일 위 표만 보시면 됩니다. 또 그 표에서 제일 마지막 measurement residuals에서 p 값이 0.05보다 크면 그럼 측정동일성을 만족한다고 결론 내리시면 되고 그 다음 남녀간 실제 조절효과를 검증하는 단계로 나가시면 됩니다.
제일 위 표의 p 값의 의미는
1) measurement weights는
귀무가설 H0: M2 모형이 맞다
대립가설 H1: M3 모형이 맞다.
2) structural covariances는
귀무가설 H0: M1 모형이 맞다
대립가설 H1: M3 모형이 맞다.
3) measurement residuals는
귀무가설 H0: M0 모형이 맞다
대립가설 H1: M3 모형이 맞다.
각 가설 검증에서 p 값이 0.05보다 크면 귀무가설 H0, 즉 간단한 모형을 선택하고 p값이 0.05보다 작으면 대립가설 H1, 즉 복잡한 모형, 이 경우 디폴트인 비제한 모형, 즉 남녀간에 뭔가 차이가 있다라는 가설을 채택합니다.
즉, 표에서 p 값이 모두 0.05보다 크게 나와야 측정동일성이 검증되었다고 안심할 수 있습니다.
amos 결과물을 보면 “디폴트 모형이 correct하다고 가정하고” 라는 말이 나오는데 이건 amos 에러이거나 아니면 앞에서 이야기한 것처럼 모형 선택 설명이 복잡해서 그냥 사용한 것이 아니가 싶습니다.
'구조방정식.매개모형,SEM,AMOS' 카테고리의 다른 글
| 잠재성장모형 모형선택 (0) | 2022.10.01 |
|---|---|
| 잠재성장모형 모형선택 (0) | 2022.09.28 |
| 구조방정식 조절효과 모형선택1 (0) | 2022.09.10 |
| 구조방정식에서 모형선택과 가설검증1 (0) | 2022.08.29 |
| 모델7:조절된 매개지수 (0) | 2022.06.21 |