이번에는 석사논문이나 저널논문에 자주 나오는 Baron & Kenny(1986)의 조절효과 검증을 혼합모형에서 어떻게 하는지 보겠습니다.
지난번에도 이야기했지만 여기서는 확률효과는 없고 오직 고정효과만 있습니다.
먼저 혼합모형 메뉴에 들어가면 첫 번째 메뉴가 뜹니다. 여기는 그냥 넘어갑니다. 이 메뉴는 패널데이터나 또는 반복측정, 또는 군집추출을 해서 아파트 단지, 병원, 또는 학교나 학급을 랜덤으로 선택할 경우만 이 메뉴를 사용합니다.
연구모형은 다음과 같습니다.
자기효능감=b0+b1*카리스마리더십+b2*연령+b3*(카리스마*연령)
여기서 성별같은 이진더미변수이면 별 문제가 없는데 연령같이 다범주, 즉 1=20대, 2=30대, 3=40-50대, 4=60대 이상 이렇게 코딩되어 있는 경우 조절효과를 보려면 연령을 3개의 이진더미 변수로 만들어야 합니다. 다음 표와 같습니다. 60대 이상을 기준범주로 취급하면
1=20대 ==> (1, 0, 0)
2=30대 ==> (0, 1, 0)
3=40-50대 ==> (0, 0, 1)
4=60대 ==> (0, 0, 0)
그래서 아래의 형태와 같은 데이터를 만들어야 합니다. 그러나 혼합모형을 사용하면 이런 작업을 일일이 할 필요가 없습니다.
| 연령 | 연령1 | 연령2 | 연령3 | |
| 1 | 1 | 0 | 0 | |
| 2 | 0 | 1 | 0 | |
| 1 | 1 | 0 | 0 | |
| 4 | 0 | 0 | 0 | |
| 3 | 0 | 0 | 1 |
그 다음 순서는 고정효과에는 요인에는 연령, 공변량(연속형 독립변수)에는 카리스마 리더십을 지정합니다. 아래 그림입니다.

그 다음 고정효과를 클릭한 다음 다음의 그림처럼 처리하면 됩니다.

연령, 카리스마 각각 추가한 다음 연령과 카리스마를 같이 지정(ALT 키 사용)하여 추가하면 됩니다. 물론 지난번 이원분산분석처럼 주효과, 상호작용효과 이렇게 일일이 지정하여 추가할 수도 있습니다.
그리고 앞의 메뉴에서 통계량을 클릭한 다음 고정효과에 대한 모수 추정값을 선택하면 결과가 회귀분석 결과처럼 나옵니다. 실제 결과를 보면 다음의 그림과 같습니다.
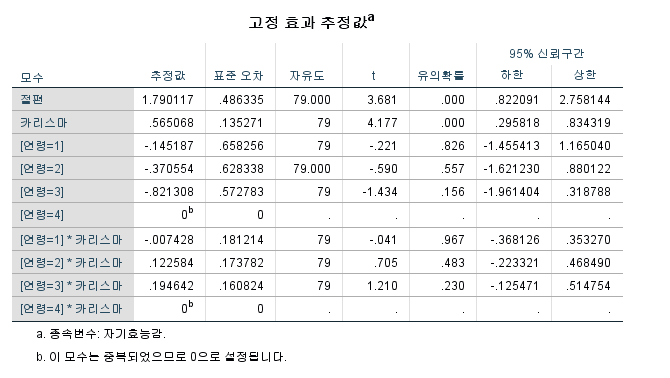
여기서 몇 가지 지적할 사항이 있습니다.
1. 통상 Baron & Kenny 조절효과 논문을 보면 1단계, 2단계, 3단계 이렇게 결과물이 나오는데 혼합모형에서는 이렇게 나올 수가 없습니다. 나오게 하려면 혼합모형을 세 번이나 일일이 돌려야 합니다.
한국 사회과학 학계에서는 이렇게 1단계, 2단계, 3단계 이렇게 분석하는 방법을 위계적 회귀분석(Hierarchical regression analysis)라고 부르고 조절효과를 볼 때 꼭 이런 방식으로 하려고 합니다.
이건 틀린 용어이고 방법론입니다. 위계적이라는 용어는 1단계, 2단계, 3단계 이런 것을 의미하는 것이 아닙니다. 마지막 3단계에서 독립변수로 상호작용항 (A*B)이 있어서 위계적이라는 용어를 사용하는 것이지 단계별로 회귀분석을 해서 위계적이라는 용어를 사용하는 것이 아닙니다.
그래서 조절효과를 보려면 마지막 3단계에 있는 상호작용항이 유의적인가 아닌가만 따지면 됩니다.
혼합모형에서는 마지막 3단계 회귀분석 결과만 보여줍니다.
단계별로 회귀분석을 하는 것은 위계적 회귀분석을 하려고 의도된 것이 아니라 모형선택(model selection) 할 때 사용하는 방법입니다.
2. 연령을 명목형처럼 취급하는 것이 맞는지 아니면 연령은 순서가 있으니까 연속변수로 취급하여 공변량에 넣은 것이 맞는지 의문이 들 수 있습니다.
정답은 없습니다. 연령에 따라 자기효능감이 쭉 증가하거나 쭉 하락하거나 이런 현상을 보일 때는 이때는 연령을 연속변수로 보아 공변량에 추가하는 것이 좋습니다. 그러나 자기효능감이 연령에 따라 뒤죽박죽 이런식으로 변하면 이 경우 연령을 명목형 변수로 취급하여 요인에 추가하는 것이 좋습니다.
3. 위계적 회귀분석할 때 논문을 보면 거의 대부분 독립변수를 표준화, 또는 평균 이동해서 하라고 나와 있습니다. 다중공선성 문제때문이 그런 것인데요 이건 옛날 통계학계에서 논란이 많이 있었던 논쟁입니다.
하여간 표준화시켜서 하려면 혼합모형 하기 전에 기술통계에 들어가서 표준화에 체크를 하면 데이터 옆에 표준화된 새로운 변수들이 추가됩니다. 그럼 이 변수들을 사용하여 혼합모형을 돌리면 됩니다.
다음은 일반적으로 하는 설문조사 데이터에서도 확률효과도 넣어서 좀 이론적으로 거창하게 보일 수 없을까 이런 생각이 들 수 있는데요. 가능합니다. 이건 다음 글에서 설명하겠습니다.
'실험계획 > 혼합모형(mixed model)' 카테고리의 다른 글
| 혼합모형으로 실험효과보기2 (0) | 2023.09.28 |
|---|---|
| 혼합모형으로 실험효과 보기1 (0) | 2023.09.25 |
| 설문데이타로 혼합모형 확률효과로 분석하기 (0) | 2023.09.23 |
| 혼합모형:이원분산분석하기 (0) | 2023.09.13 |
| 혼합모형의 이해1 (0) | 2023.08.10 |