지난번에 SPSS에서 분산분석을 일반선형모형으로 할 수 있고, 또 구체적으로 범주형 자료를 이진더미 만들어 회귀분석에서도 할 수 있다고 했습니다.
그럼 어떻게 이진변수를 만들고 또 결과를 어떻게 해석하는지 한번 보시죠.
먼저 지난번 결과를 다시 한번 보죠.

분산분석에서 평균을 보면 조직구조별 조직몰입 평균은
조직1은 평균 3.96, 조직2는 평균 3.35, 조직3은 평균 2.88입니다.
이걸 일반선형모형 결과나 회귀분석 결과에서 보면

조직1=상수+[조직구조=1]=2.883+1.076=3.96
조직2=상수+[조직구조=2]=2.883+0.465=3.35
조직3=상수=2.88
반올림 빼면 정확하게 일치합니다.
그럼 변수명을 조금 현실적으로 바꿔서
조직몰입=사회혼란, 조직구조=종교로 하고
종교=1는 기독교, 종교=2는 불교, 종교=3은 무교로 하겠습니다.
그래서 우리의 관심은 종교별로 한국사회의 혼란 인식이 어떻게 차이가 있는지 분석하는 것입니다.
그런데 나이가 많을수록 한국사회가 혼란하다고 인식할 가능성이 많기 때문에 연령을 통제변수로 넣었습니다.
그래서 일반선형모형에서 고정요인은 종교, 공변량은 연령을 넣습니다.
그리고 메뉴에서 모델은 고정요인이 2개 이상이 아닌 경우 그냥 놔둬도 됩니다. 이건 분산분석에서 모델 선택의 문제인데 이것까지 설명하면 너무 복잡하니까 생략합니다.
그리고 옵션에서 parameter estimation을 체크해야 합니다. 그래야 회귀분석 결과가 나옵니다.
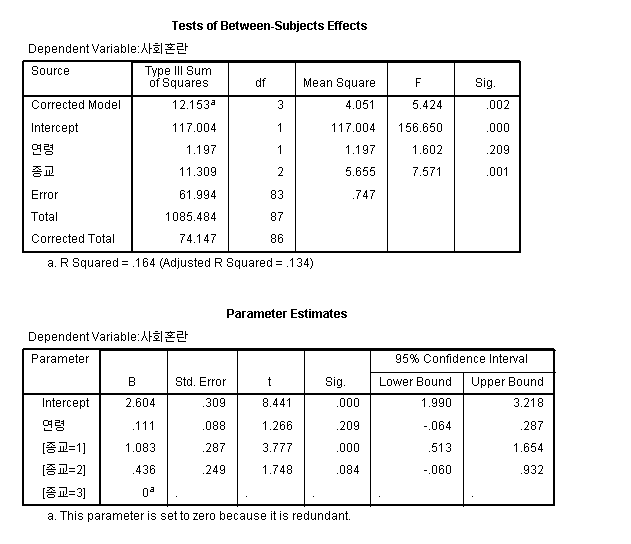
위 결과를 보면 연령은 p=0.209로 유의수준 0.05에서 유의하지 않습니다. 또 종교에서는 F=7.571, p=0.001로 유의하게 나옵니다.
즉, 해석은 사회혼란 인식에 영향을 미칠 수 있는 연령의 효과를 통제한 다음, 즉 연령의 효과를 뺀 순수한 종교에 따른 사회혼란 인식에서도 유의적인 차이가 있다 이렇게 해석이 되는 것입니다.
그럼 회귀분석 결과는 어떻게 될까요. 회귀분석 결과는 SPSS에서 다음과 같이 나옵니다.

위의 일반선형모형과 결과가 똑 같습니다. 그럼 어떻게 기독교, 불교 이진변수를 만들 수 있을까요. 이건 제 블로그에서 많이 설명했는데 다음과 같습니다. 여기서 종교=1은 기독교, 종교=2는 불교, 종교=3은 무교입니다. 범주형 자료도 숫자로 만드는 것이 좋고, 그 대신 코딩북을 만들어서 항상 기록해야 합니다.
| 종교 | 기독교 | 불교 |
| 1 | 1 | 0 |
| 2 | 0 | 1 |
| 3 | 0 | 0 |
| 3 | 0 | 0 |
| 2 | 0 | 1 |
| 1 | 1 | 0 |
즉, 2개의 이진변수 (기독교, 불교)는 무교=(0,0), 기독교=(1,0), 불교=(0,1)로 코딩해야 합니다.
이렇게 코딩한 다음 종속변수에 사회혼란인식, 그리고 연령, 기독교, 불교 이진더미 변수를 독립변수에 투입하면 됩니다.
그럼 이런 질문을 할 수 있습니다. 연령은 통제변수인데 다르게 취급해야 하는 것이 아니냐고요.
그럴 필요없습니다. 통제변수를 넣는다는 것은 그냥 회귀분석에서 독립변수로 넣는다는 것과 같은 것입니다. 회귀분석에서는 어떤 특정 독립변수의 해석은 나머지 다른 변수가 투입된 이후 이 특정 독립 변수의 추가적인 영향력의 개념이기 때문입니다.
그럼 기독교, 불교 변수 자체만 해석하면 다음과 같습니다.
기독교 이진변수의 경우 기독교=1, (불교, 무교)=0, 그래서 변수 자체만 해석하면 회귀계수를 기독교와 기독교 아닌 사람과의 차이, 즉, 불교나 무교인 사람과의 차이,
불교 이진변수의 경우 불교=1 , (기독교, 무교)=0, 그래서 변수 자체만 해석하면 회귀계수를 불교신자와 불교 신자가 아닌 사람, 즉 기독교나 무교인 사람과의 차이 이렇게 해석됩니다.
그러나 실제 회귀분석 결과는 이렇게 해석하면 안됩니다.
회귀분석 식을 실제로 쓰면
사회혼란인식=b0+b1*연령+b2*기독교+b3*불교
이렇게 되는데,
그럼
무교인 사람의 경우는 (기독교, 불교)=(0,0) 이렇게 되어
사회혼란인식=b0+b1*연령
기독교인 경우 (기독교, 불교)=(1,0) 그래서
사회혼란인식=b0+b1*연령+b2
불교의 경우 (기독교, 불교)=(0,1) 그래서
사회혼란인식=b0+b1*연령+b3
이렇게 됩니다. 그래서 기독교의 회귀계수 b2는 무교인 사람과 기독교인 사람과의 상수항의 차이, 불교의 회귀계수 b3는 무교인 사람과 불교인 사람과의 상수항의 차이 이렇게 해석이 됩니다.
그리고 연령을 통제한 이후 무교와 기독교와의 사회혼란 인식은 회귀분석 표에 보면 t=3.777, p=0.000으로 유의적인 차이가 있습니다.
그러나 연령을 통제한 이후 무교와 불교와의 사회혼란 인식은 표에 보면 t=1.748, p=0.084로 약간 애매모호합니다. 유의수준을 0.05로 잡으면 유의적인 차이가 없다고 보고, 유의수준을 0.1로 잡으면 유의적인 차이가 있다고 봅니다.
일반사회과학에서는 무조건 SPSS 관례에 따라 유의수준을 0.05로 잡는데 이 기준이 진실이 아닙니다. 경제학 논문들 보면 거의 다 유의수준을 0.1로 잡습니다. 통계학과에서는 유의수준 잡는 것은 분석하는 사람 마음대로다 이렇게 되는 것이고요. 그러나 관행적으로 0.1(신뢰구간에서는 90%), 0.05(신뢰구간에서 95%), 0.01(신뢰구간에서는 99%) 이렇게 많이 하죠.
그러나 이 결과에서는 기독교인과 불교인과의 사회혼란 인식에서 차이에 대한 검증은 알 수 없습니다.
그럼 해석에서 왜 이렇게 차이가 날까요. 기독교 변수 자체를 보면 기독교인과 비기독교인(무교와 불교)의 차이 이렇게 해석되는데 회귀분석 결과는 왜 무교와 기독교인과의 차이 이렇게 해석이 될까요.
이건 회귀계수가 수학에서 편미분에 해당되기 때문입니다. 즉 회귀분석에서 어떤 독립변수의 회귀계수는 다른 독립변수의 값이 일정하다는 가정하에서 기울기이기 때문입니다.
즉 기독교 독립변수의 기울기 해석은 다른 변수 불교라는 변수도 고려해서 해석을 해야 합니다. 기독교 회귀계수는 다른 변수 불교라는 변수가 같은 값일 경우 기울기이라는 것이죠. 너무 복잡하게 생각하시지 말고 이런 현상이 있다는 것만 아시기 바랍니다.
이걸 그림을 그리면 다음과 같습니다.

이 그림은 R에서 그린 것입니다.
그림을 보면 상수항이 종교별로 차이가 있습니다.
만약 기울기마저 종교별로 차이가 있다면 이젠 이건 조절효과를 보는 것입니다.
지금 이 모형은 혼합모형의 단순한 형태와 비슷합니다. 일반적으로 혼합모형은
Y=(b0+F)+(b1+F)*X+e
상수항에서는 고정효과 F가 있지만 기울기에서는 고정효과가 없는 단순한 모형의 경우입니다.
'혼합모형(Mixed Model)' 카테고리의 다른 글
| 혼합모형의 이해1 (0) | 2022.01.10 |
|---|---|
| 범주형 자료처리:이원분산분석, 조절효과 (0) | 2021.12.19 |