댓글을 보니까 조절효과 관련해서 범주형 자료 처리하는 것에 관해 많이들 질문을 하시는 것 같습니다.
그래서 이 범주형 자료 처리를 SPSS에서 어떻게 하는지 이야기를 좀 할까 합니다.
아마 다룰 분석은 SPSS에 있는 분산분석(일원 분산분석), 그리고 일반선형모형(general linear model), 회귀분석(Regression Analysis), 그리고 혼합모형(Mixed model)이 될 겁니다.
SPSS에서는 메뉴에 일반선형모형(general linear model)과 일반화 선형모형(generalized linear models)가 있는데 일반화 선형모형은 아마 여러분이 거의 할 기회가 없을 겁니다.
일반화 선형 모형은 종속변수가 정규분포가 아닌 포아송 분포라든지 지수분포 이런 변수들일 경우 사용하는 방법입니다.
먼저 범주형 자료를 처리하는 가장 흔한 분석이 분산분석(ANOVA)인데 이 분야는 사실 실험계획(experimental design)이라는 분야를 말합니다.
이 분야가 통계학에 일반 현실 분야에 가장 많이 응용되고 도움이 많은 되는 분야인데 많이 알려져 있지 않고 그리고 이쪽에 전공하는 사람도 별로 없습니다.
많이 사용되는 분야가 농수산업, 임업 등 어떤 방법을 썼을 경우 수확량이 언제 가장 좋은지 이런 분석을 하는 경우입니다. 또는 코로나 사태와 같이 어떤 약품이 가장 효과가 있는지 이런 분석을 하는 경우입니다.
이런 경우 설문조사 하듯이 몇백명, 몇천명 바로 할 수 없거든요. 임업이나 농수산업의 경우 결과를 보려면 최소한 1-2년 걸리고 제대로 하려면 전국에 몇 십군데, 몇 백군데에서 실험을 해야 하는데 시간과 비용이 엄청나다는 것이죠. 의료실험은 윤리적인 문제로 쉽게 실험을 실시할 수 없습니다.
그래서 제한 된 상황 아래에서 가장 효과적으로 실험을 할 수 있는 다양한 실험 방법 등을 공부하는 분야입니다.
그러나 다양한 실험 방법이 제기되어도 그 밑바탕이 되는 이론은 결국 분산분석(ANOVA:Anlaysis of Variance)입니다.
그래서 통계학 공부하는 사람 입장에서는 재미없는 분야이죠. 예를 들어 지금 통계학과에서는 거의 다 인공지능 이런 쪽 공부하려고 하지 이런 분산분석 이런 분야 전공하려고 하겠습니까.
분산분석이란 말은 이런 의미입니다. 어떤 비료를 사용했을 때 수확량이 가장 많을까 이런 문제를 고민한다고 하죠.
그럼 비료 A, B, C에 따라 수확량의 전반적인 차이가 있을 것입니다. 사용된 비료의 종류에 따른 수확량의 변동, 즉 분산이 있을 겁니다. 이걸 집단간 변동이라 합니다.
그리고 똑 같은 비료 A를 사용해도 그 안에서 또 수확량의 차이, 즉 변동, 분산이 있을 겁니다. 이걸 집단내 변동이라 합니다.
그래서 대강 이야기하면 이 변동의 상대적인 비율 즉 F=(집단간 변동/집단내 변동)이 크면 투입한 비료의 종류에 따라 수확량의 유의적인 차이가 있다고 판단하는 것입니다.
흔히 논문에서 많이 하는 분산분석은 인구통계 변인별로 연구변수에서 차이가 있는지 보는 것입니다. 즉, 성별, 연령, 학력, 종교, 결혼여부, 자녀수, 경제수준, 건강수준에 따라 우울, 직무만족, 삶의 만족도에서 차이가 있는지 이런 분석을 하는 것입니다.
옛날에 통계를 많이 사용하지 않았을 때는 이 분산분석을 많이 했습니다. 통계 분석량이 10페이지 정도 늘어날 수 있죠. 양 떼우기 좋은 분석이죠.
지금은 이런 분석해서 논문 량을 채우면 아마 다 지우라고 할 수 있습니다.
그럼 이 분석은 SPSS에서 간단합니다.
Analyze ==> Compare Means ==> One-way ANOVA
하시고 종속변수에 우울, 직무만족, 삶의 만족도 이런 변수들 집어 넣으시고, Facor에 성별, 연령, 학력, 기타 등등을 집어 넣으시면 됩니다.
성별의 경우는 t 검증인데 이 t 값을 제곱하면 분산분석의 F값이 됩니다. 그래서 t 검증도 분산분석의 일종이라 보셔도 됩니다.
이 분산분석은 투입된 요인별로 종속변수에서 유의적인 차이가 있는지 이것만 보는 것이지 구체적으로 요인의 뭐와 뭐가 차이가 있다 이런 것까지 볼 수 있는 것이 아닙니다.
예를 들어 분산분석 결과에서 학력별로 삶의 만족도에서 차이가 있다 이런 이야기는 나오지만 구체적으로 중졸 이하 학력자와 대졸 이상 학력자가 삶의 만족도에서 차이가 있다 이런 구체적인 결과까지 내 주지 않습니다.
그럼 이걸 하려면 사후검증이라는 것을 또 하셔야 합니다. 이걸 하려면 분산분석에서 사후검증(post hoc) 메뉴를 체크해야 합니다. 보면 수 많은 사후검증 방법이 있는데 던컨 정도 하시면 됩니다.
그럼 여기서 두 가지 문제가 있을 수 있습니다.
1)
하나는 투입되는 요인이 하나가 아니라 두 개 이상일 경우 어떻게 하는가?
2)
만약 통제할 수 없는 어떤 변수가 영향을 미칠 경우 이런 변수들을 어떻게 처리할 것인가 하는 문제입니다.
예를 들어 1) 문제는 이런 경우입니다.
비료 A, B, C에 따라 수확량이 달라지는지 보고 싶은데 이게 또 실험하는 토양의 성격에 따라 또 달라질 수 있거든요. 즉 토양이 산성, 중성, 알칼리 일 경우 또 수확량이 달라질 수 있다는 것이죠.
그럼 이 경우 이원 분산분석(Two-way ANOVA)를 해야 합니다. 그러나 이 이원 분산분석부터는 문제가 좀 복잡해집니다. 즉 투입한 비료와 토양간의 상호작용이 생길 수가 있다는 것이죠.
그래서 비료만 투입한 매우 간단한 일원 분산분석은 모형은 간단합니다.
산출량(ij)=u(전체 평균)+a(i)(투입한 비료에 의한 산출 증가나 감소)+e(ij)
이렇게 되는데
이원 분산분석은
산출량(ij)=u+a(i)+b(j)+ab(ij)+e(ijk)
이렇게 좀 복잡하게 나옵니다. 여기서 a(i)는 비료의 영향, b(j)는 토양의 영향, e는 모형이 설명하지 못하는 오차항입니다.
2) 문제는 이런 것입니다.
좋습니다. 농작물의 수확량은 투입된 비료 종류와 토양 산성정도, 그리고 그 상호작용에 의해 영향을 받는다고 합시다. 그럼 실험 기간 동안 강우량도 많이 다를겁니다. 그럼 이 강우량의 영향을 어떻게 처리할 것인가 하는 문제가 생깁니다.
이 경우 강우량을 통제변수로 처리한다고 합니다. 통제변수는 우리의 원래 관심 변수가 아닙니다. 우리의 관심은 비료 종류와 토양의 산성 정도가 수확량에 미치는 영향이지 강우량이 수확량에 미치는 영향을 분석하는 것이 목적이 아닙니다.
그러나 분명히 강우량도 종속변수인 수확량에 영향을 미친다고 생각하면 이 강우량의 영향을 분석에서 통제를 해야 하는 것입니다. 그래야 순수한 비료 종류와 토양의 산성정도가 수확량에 미치는 영향을 분석할 수 있는 것입니다.
이 1)과 2) 문제의 경우 일반 선형모형(general linear model)을 사용하면 됩니다.
일반선형모형==> univariate ==> 종속변수에 수확량, 고정 요인에 비료종류, 토양 산성 정도, 그리고 공변량에 강우량을 투입하시면 됩니다.
그리고 model에서 상호작용까지 보고 싶으면 그냥 놔두면 되고, 상호작용항이 없는 모형을 하고 싶으면 custom ==> build term에서 비료종류와 산성정도 두 개의 요인의 주효과(main effect)를 선정하면 됩니다. 그리고 여기서도 사후검증을 하시고 싶으면 메뉴에서 Post Hoc을 지정하시면 됩니다.
만약 사전과 사후 사이에 어떤 treatment를 했을 경우 이 처리의 효과가 있는지 볼 경우, 즉 교육방법론, 또는 제약이나 의료 치료에서 많이 하는 방법이죠. 이 경우 처리를 한 실험집단과 사전, 사후에 아무런 처리도 하지 않는 통제집단을 만들어 집단이라는 하나의 변수를 만들어 실험을 합니다.
이 경우 고정요인에 집단(즉 통제집단=0, 실험집단=1로 처리한 변수)을, 공변량에는 사전 점수를 투입하면 공변량 분석이 되어 실험의 효과를 검증할 수 있습니다.
또 이 일반선형모형은 앞에서 한 하나의 요인만 들어가는 일원분산분석도 당연히 되겠죠. 고정요인에 비료종류 하나만 넣으면 그냥 일원분산분석이 되고 이 경우 결과물은 compare means의 일원분산분석 결과와 같습니다.
일원분산 분석 결과입니다. 즉 compare means==> one-way anova 한 결과입니다.

다음은 이 분석을 general linear mdoel 분석을 한 결과입니다.

F=7.282, p=0.001로 같죠.
그리고 아래 parameter estimates은 이 분산분석을 회귀분석으로 한 것입니다.
다음은 실제로 조직구조라는 범주형 자료를 구체적으로 조직구조1, 조직구조2라는 2개의 더미 변수로 만들어 spss에서 Regression Analysis, 즉, 회귀분석을 하였을 경우 나온 결과입니다.
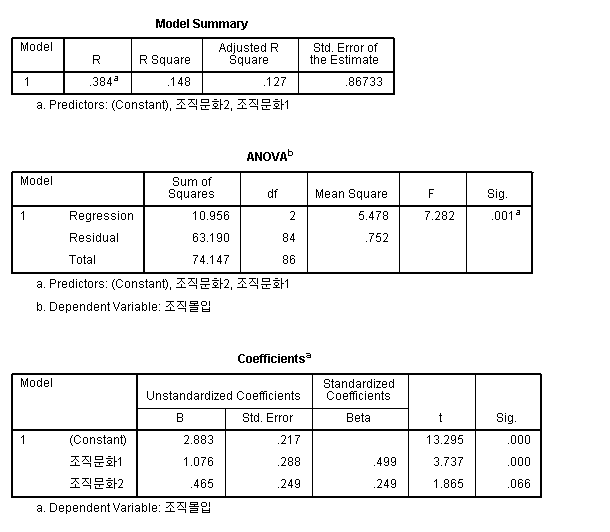
여기서도 F=7.282, p=0.001로 같게 나오죠. 그리고 회귀계수 값도 위의 일반선형모형 결과와 똑 같습니다.
즉, 일원분산분석은 SPSS에서
1) compare means==> one-way ANOVA 할 수도 있고,
2) general linear model 에서도 할 수 있고,
3) 그리고 범주형 요인을 2개나 3개의 더미 변수를 새로 만들어 Regression Analysis에서 처리할 수 있습니다.
그럼 다 똑같은 결과를 얻을 수 있습니다.
그럼 다음에는 구체적으로 어떻게 회귀분석 형태로 만드는지, 그리고 이 경우 회귀분석 결과를 어떻게 해석하는지 설명을 드리겠습니다.
'혼합모형(Mixed Model) > 혼합모형의 이해와 수식' 카테고리의 다른 글
| variance component (0) | 2022.07.23 |
|---|---|
| 혼합모형(Mixed Model) 이해와 수식 (2) | 2019.03.26 |