오늘은 구조방정식에서 조절효과 보는 방법에 대해 이야기를 하겠습니다.
전에 한번 쓴 적이 있는데 그때는 저도 한국에 나온 책을 보고 썼는데 작업을 계속 하다 보니까 그 내용들이 명확치도 않고 또 작업하다가 이리저리 하다 보니까 좀 정리를 할 필요가 있을 것 같아서 다시 업데이트를 합니다.
생각보다 하는 방법은 간단합니다. 순서를 꼭 지켜야 하는 경우는 분명하게 언급을 합니다.
주의: AMOS에서 Model은 전혀 손 될 필요가 없습니다.
1) 조절변수를 표준화하고 표준화된 변수를 이진더미변수로 바꿉니다.
이건 SPSS에서 기술통계 구할 때 표준화 메뉴에 체크를 하면 자동적으로 표준화된 조절변수가 데이터에 추가됩니다. 표준화 변수는 평균이 0이고 표준편차가 1인 변수입니다.
따라서 이진더미 변수로 만들 때 transform==>다른 변수로 변환로 가서 0이하=>0, 0 이상=>1로 더미변수로 만듭니다.
기술통계는 상관관계 분석과 함께 모든 논문에서 기본적으로 해야 하는 기초분석입니다. 따라서 관련된 연구변수 기술통계 구할 때 조절변수로 같이 하시면 됩니다. 그리고 Baron & Kenny(1986)의 위계적 회귀분석을 통해 조절효과 구할 때도 다중공선성 문제로 표준화를 해야 하기 때문에 이 기술통계 구할 때 표준화변수로 구해 달라고 꼭 체크를 하시기 바랍니다.
2. 다음과 같은 가장 간단한 구조방정식 부분 매개 모형을 가정하죠.
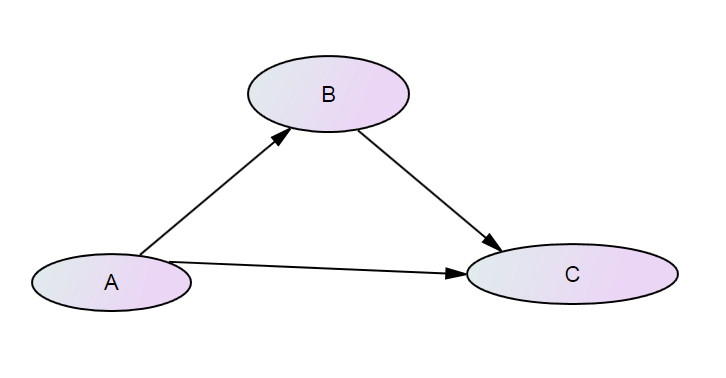
그림 AMOS에서 그림 왼쪽에 있는 group에서 또 다른 group를 만듭니다. 이건 group을 클릭하면 됩니다.
조절변수가 성별이면 group1은 남자, group2는 여자 이렇게 이름을 붙이고, 아니면 연속변수를 이전더미 변수로 만들었다면 저집단, 고집단 이렇게 이름을 붙이면 됩니다. 이름을 따로 새로이 붙이지 않아도 됩니다. 그러나 하는게 헷갈리지 않아서 이름을 붙이는 것을 권유합니다.
group 밑에 default model이라고 있는데 이건 전혀 손 볼 필요가 없습니다. 국내에 나와 있는 책들이 이 모델이라는 개념을 이해를 못해서 이걸 자꾸 손대라고 나와 있는데 이거 전혀 하실 필요가 없습니다. 이건 나중에 설명 드리겠습니다.
3. 이것 한 다음 이 group1과 group2가 어떤 데이터와 연결되어 있는지 알려줘야 합니다. 위의 1.과 2. 과정을 꼭 먼저 해야 합니다.
group1에 해당하는 데이터와 group2에 해당하는 파일을 SPSS에서 만들 필요는 없습니다.
그냥 AMOS에서 File==> Data files 가셔서 처리하면 됩니다. 그룹이 저집단, 고집단 이렇게 되어 있으면 저집단에 체크한 다음 data file에 가서 원 데이터 지정하고 그 다음 group variable에서 이진더미 변수로 만든 조절변수를 지정합니다. 그리고 group value에서 0을 지정합니다.
그 다음 고집단을 체크한 다음 다시 data file에서 group variables와 group value에서 1을 지정합니다.
4. 그 다음 2개의 집단 즉, 저집단과 고집단의 경우 위의 연구모형의 회귀계수을 일일이 지정해야 합니다.
먼저 저 집단의 경우 아래 그림처럼 회귀계수에 a1, a2, a3 이름을 지정합니다.
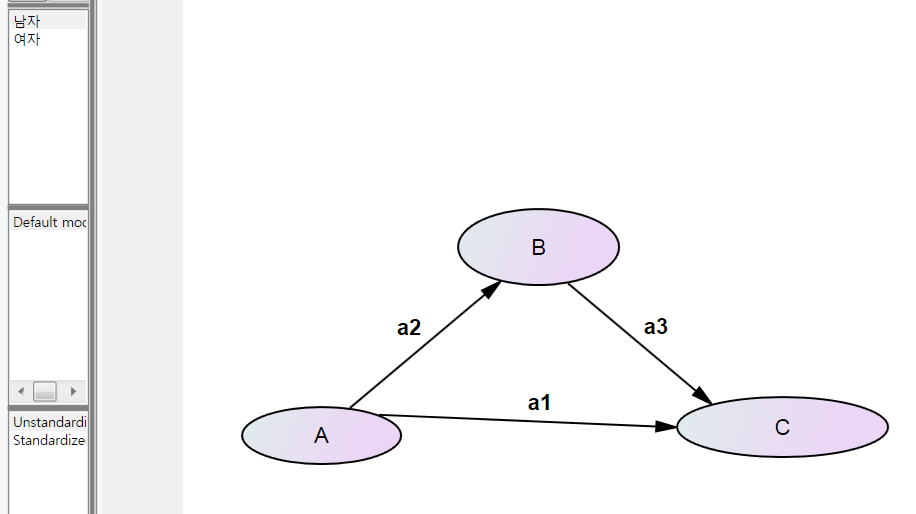
이때 주의할 것은 all group이 디폴트로 체크가 되어 있는데 이것을 지워야 합니다. 체크가 되어 있으면 group2도 자동적으로 a1, a2, a3 이름이 붙습니다. 이것 꼭 지우기 바랍니다.
그 다음 group2에서도 아래 그림과 같이 똑같이 회귀계수 이름을 붙여 줘야 합니다. b1, b2, b3 이렇게요.
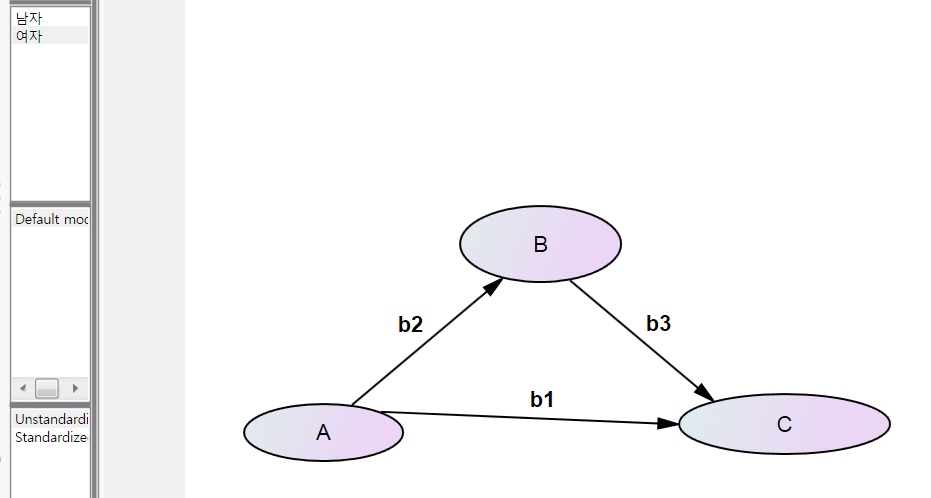
그런 다음 실행을 하면 끝입니다.
5. 주의점
1) view==> analysis properties==> output에서 critical ratios for differences를 꼭 체크해야 합니다. 이게 조절효과 보는 것입니다. 이걸 하면 나중에 결과물에서 z값을 보여 줍니다.
이건 결과물에서 저집단, 고집단 누르고 estimate 누르면 저집단과 고집단의 경우 회귀계수 값을 보여주고 그 다음 pairwise parameter comparisons 누르면 z 값을 보여줍니다. 유의수준은 보여 주지 않습니다. 이게 결과물 메뉴에 없으면 1)번을 하지 않은 것입니다.
z는 표준정규분포를 말합니다. 이 z 값이 1.96보다 크면 p<.05, 2.64보다 크면 p<.01 이렇게 됩니다. 많이 본 숫자들이요.
2) Bootstrap은 하지 마세요. 조절효과는 바로 수학적으로 풀어집니다. 구태여 시뮬레이션 할 필요가 없습니다. 우리가 보는 것이 두 집단에서 나온 회귀계수의 차이가 유의한지, 아니지, 즉 차이가 0인지 0이 아닌지 보는 것인데
(a1-b1), (a2-b2), (a3-b3)을 보는 것인데 이건 수학적으로 바로 계산이 됩니다.
3) 혹시 표준화에서 문제가 있다고 오류 메시지가 뜨면 output에서 standardized estimates 이 메뉴에서 체크를 해제하시기 바랍니다.
이것 필요없습니다. 제 경험으로 보면 조절효과보는 z값의 부호가 비표준화 회귀계수 가지고 하는 것 같습니다. 표준화 회귀계수를 가지고 표를 만들면 z값을 부호와 일치하지 않는 경우가 생깁니다.
4) 만약 구조방정식 화살표 전부 다 조절효과가 보는 것이 아니고 일부분 화살표만 볼 경우는 어떻게 할까요. 그냥 그 화살표만 회귀계수 이름을 붙이면 됩니다. 다른 것은 전혀 손되지 않고요. 즉 group1에서는 a2, group2에서는 b2 이렇게 지정하고 다른 화살표는 그냥 놔두면 됩니다.
5) 그럼 책에 보면 model를 2개 만들어 복잡하게 설명되어 있는데 이건 왜 하는 것이죠 이렇게 물어 보실 수 있습니다. 앞에서도 이야기했지만 이것 전혀 하실 필요가 없습니다.
이것 하면 카이제곱 값을 구해 주는데 혹시 논문 심사위원이 카이제곱 값을 넣어라 하면 이걸 해야 합니다.
이것 하는 방법은 group가 마찬가지로 default model를 클릭하면 또 하나의 모델을 만들 수 있습니다. 이름도 붙힐 필요가 없습니다. 그리고 이 중 하나의 모델에서
a1=b1
a2=b2
a3=b3
이렇게 제한조건을 넣어 주시면 됩니다. 그리고 돌리면 결과물 맨 밑에 model에 관한 값이 나옵니다. 여기에 카이제곱 값이 나옵니다.
그럼 이건 도대체 뭘 이야기하는 것일까요.
이건 회귀분석 할 때 나오는 F 검증과 같은 것이라 생각하시면 됩니다.
회귀분석하면 F 검증과 t 검증이 나오는데 우리가 진짜 필요한 것은 t 검증입니다. 즉 어떤 변인이 유의적인 영향력이 있는지 판단하는 것은 t 검증이지 F 검증이 아닙니다.
F 검증은 회귀계수 b1, b2, b3 중 최소한 하나는 0이 아니다, 즉 최소한 하나의 변수는 유의적인 영향력이 있다 이걸 보는 것입니다.
그래서 F 검증에서 유의적으로 나와도 이런 질문이 나옵니다. 그럼 하나는 유의적인 영향력이 있는데 도대체 어떤 독립변수가 유의적인 것이나 하는 질문요.
그래서 다시 t 검증을 보는 것입니다. 구체적으로 어떤 독립변수가 유의적인 영향력이 있는지를요.
마찬가지입니다. 여기서 카이제곱은 (a1, b1), (a2, b2), (a3, b3) 이 세 개중 최소한 하나가 차이가 있다는 것을 말하는 것입니다. 그럼 회귀분석과 마찬가지로 그럼 도대체 이 3개 (a1, b1), (a2, b2), (a3, b3) 중 어떤 것이 차이가 있다는 말인가 하는 질문이 나온다는 것이죠. 여기에 대한 대답이 바로 z검증입니다.
결국 카이제곱 검증으로는 실제로 아무런 대답을 할 수 없고, 결국 z 검증 값을 보고 어디서 조절효과가 있는지 판단을 해야 한다는 것입니다.
'구조방정식.매개모형,SEM,AMOS > 구조방정식,매개모형,SEM,AMOS' 카테고리의 다른 글
| 잭나이프(jacknife)와 부트스트랩 (bootstrap)간단 이해 (0) | 2020.06.23 |
|---|---|
| 구조방정식 할 때 주의사항 (0) | 2019.12.28 |
| 구조방정식에서 조절효과 검증 (0) | 2019.06.04 |
| 구조방정식에서 수정모형 만들기 (0) | 2016.05.12 |
| 구조방정식에서 조절효과 (0) | 2016.05.12 |